Há cerca de dois anos um amigo (o Carlos Diego) me chamou não lembro em qual chat e mostrou o trabalho da geógrafa Fejetlenfej. Ela produziu mapas colorindo as bacias hidrográficas dos EUA, criando um efeito belíssimo.
Antropólogo e mestrando em gestão e regulação de recursos hídricos, ele viu naqueles mapas uma forma diferente e sensível de explicitar a importância dos rios em nossa relação com o espaço e os territórios. Resolvemos então reproduzir a ideia usando dados da hidrografia brasileira.
Com um certo trabalho, na época fizemos os mapas no QGIS. Depois o Diego publicou na plataforma aguas.ml e logo em seguida no Archdaily Brasil, onde por muitos dias foi a publicação mais acessada do site.
Muita gente perguntou como fazê-los, mas a reprodutibilidade não é um forte do QGIS. De lá para cá eu incorporei minhas habilidades em visualização de dados e há um bom tempo quero parar e fazer estes mapas no R. Alguns dias atrás parei e fiz isto (há coisas que fazemos por diversão).
Agora eu explico neste tutorial como criar este arco-íris das veias brasileiras usando dados abertos disponibilizados pela Agência Nacional de Águas (ANA) e de forma programática. Se voce copirar esse .Rmd e rodar no seu computador, replicará todo o processo! Com algumas alterações, você poderá criar mapas de variadas escalas e destacar os rios de lugares diferentes.
Obter os dados
Para começar é preciso obter os dados. Utilizaremos duas bases de dados em formato shapefile.
A primeira delas contem a geolocalização dos cursos d’água do território nacional, representados geometricamente por linhas. Embora já exista a versão de 2017, mais recente, utilizaremos a base de 2013, que é muito mais leve.
A segunda base tem a geometria poligonal das regiões hidrográficas brasileiras. A necessidade desta base ficará clara mais abaixo.
Então, vou baixar os dados:
# # baixar shapefile de cursos d'água
# dir <- "data-raw/geoft_bho"
# url <- "https://metadados.ana.gov.br/geonetwork/srv/en/resources.get?id=267&fname=geoft_bho_cursodagua.zip&access=private"
#
# # Obter os dados
# if (!file.exists(dir)) {
# tmp <- tempfile(fileext = ".zip")
# curl_download(url, tmp)
# unzip(tmp, exdir = dir)
# unlink(tmp)
# }
#
# dir <- "data-raw/SNIRH_regioes_hidrograficas"
# url <- "http://metadados.ana.gov.br/geonetwork/srv/pt/http://metadados.ana.gov.br/geonetwork/srv/en/resources.get?id=92&fname=SNIRH_RegioesHidrograficas.zip&access=private"
#
# if (!file.exists(dir)) {
# tmp <- tempfile(fileext = ".zip")
# download.file(url, tmp)
# unzip(tmp, exdir = dir)
# unlink(tmp)
# }O código axima realizou o download do arquivo zipado, descompactou e guardou os arquivos extraídos em um diretório chamado data-raw/geoft_bho, localizado na raiz do seu diretório de trabalho.
Carregar pacotes e importar dados
Após baixar os dados já é possível importá-los no ambiente do R. Antes vamos carregar os pacotes que serão utilizados.
sf: as operações com os dados espaciais serão feitas com o pacotesf, que implementa o padrão simple features no R.dplyr: para manipulação de dados não espaciaisggplot2: para a criação dos mapasstringr: para a manipulação de stringspurrr: para plotar os mapas das RHI em looping
Caso não tenha os pacotes instalados, é preciso instalar.
As linhas de código a seguir dão conta de instalar todos os pacotes necessários.
# instalar pacotes
install.packages("sf")
install.packages("tidyverse") # dplyr, ggplot2, stringr e outros
devtools::install_github("bruno-pinheiro/seda")E agora vamos carregar os pacotes:
# carregar pacotes
library(sf)
library(tidyverse) # dplyr, ggplot2, stringr e outros
library(seda)O próximo passo é importar os dados.
# Importar os dados
cursos <- read_sf("data-raw/geoft_bho_cursodagua/geoft_bho_cursodagua.shp")
regioes <- read_sf("data-raw/SNIRH_RegioesHidrograficas/SNIRH_RegioesHidrograficas.shp")Os dados já estão disponíveis no ambiente de trabalho. Vamos dar uma olhada rapidamente neles, para saber com o que estamos lidando:
head(cursos)## Simple feature collection with 6 features and 11 fields
## geometry type: MULTILINESTRING
## dimension: XY
## bbox: xmin: -65.64893 ymin: -18.06182 xmax: -55.30987 ymax: -8.016336
## epsg (SRID): 4674
## proj4string: +proj=longlat +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +no_defs
## # A tibble: 6 x 12
## WTC_PK IDCDA COCURSODAG NUDISTBACC NUCOMPCDA NUAREABACC COCDADESAG
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <chr>
## 1 108774 108774 895989422 3156. 1.46 1.11 89598942
## 2 75216 75216 4448 2336. 411. 13545. 444
## 3 256913 256913 446 1934. 774. 59112. 44
## 4 256020 256020 4634 2171. 904. 64719. 46
## 5 202146 202146 46362 2313. 435. 13315. 4636
## 6 56949 56949 46382584 2750. 2.25 25.8 4638258
## # … with 5 more variables: NUNIVOTCDA <int>, NUORDEMCDA <int>,
## # DEDOMINIAL <chr>, DSVERSAO <chr>, geometry <MULTILINESTRING [°]>Ao todo o objeto cursos tem mais de 310 mil linhas representado os cursos d’água do Brasil e um conjunto de 12 atributos não espaciais a respeito deles. Não há, porém, uma variável indicando a qual região hidrográfica o rio pertence.
head(regioes)## Simple feature collection with 6 features and 5 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -57.64388 ymin: -31.82839 xmax: -34.7931 ymax: -0.5352369
## epsg (SRID): 4674
## proj4string: +proj=longlat +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +no_defs
## # A tibble: 6 x 6
## RHI_SG RHI_CD RHI_NM RHI_AR_KM2 RHI_VE geometry
## <chr> <dbl> <chr> <dbl> <chr> <MULTIPOLYGON [°]>
## 1 J 12 URUGUAI 174128. 2014 (((-53.3646 -26.24709, -53.363…
## 2 C 3 ATLÂNTIC… 268906. 2014 (((-47.71067 -0.5365409, -47.7…
## 3 D 9 PARNAÍBA 331809. 2014 (((-41.78675 -2.744119, -41.78…
## 4 E 4 ATLÂNTIC… 285281. 2014 (((-41.78202 -2.757152, -41.78…
## 5 F 10 SÃO FRAN… 636137. 2014 (((-39.89673 -7.262451, -39.89…
## 6 G 2 ATLÂNTIC… 386068. 2014 (((-39.32715 -9.595747, -39.32…É para isto que servirá o objeto regioes. Nele constam os 12 polígonos das regiões hidrográficas e 6 variáveis, sendo de nosso interesse RHI_CD e RHI_NM (respectivamente código e nome da região).
Preparar os dados
Limpar variáveis e reprojetar
Antes de avançar, vamos limpar as variáveis que não serão usadas e ajustar a projeção. As duas bases estão configuradas com um sistema de referências de coordenadas latlong, então transformarei a projeção para UTM, particularmente o CRS Sirgas 2000 / UTM zone 23, cujo código EPSG é 31983.
cursos <- cursos %>% select(COCURSODAG, NUCOMPCDA) %>% st_transform(31983)
regioes <- regioes %>% select(RHI_NM, RHI_CD) %>% st_transform(31983)Podemos conferir a nova projeção definida com st_crs():
st_crs(cursos)## Coordinate Reference System:
## EPSG: 31983
## proj4string: "+proj=utm +zone=23 +south +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs"st_crs(regioes)## Coordinate Reference System:
## EPSG: 31983
## proj4string: "+proj=utm +zone=23 +south +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs"Tudo ok. Tanto a projeção está correta, como os dois objetos têm o mesmo CRS. Posso seguir adiante.
Agora, vou criar um plot dos rios com mais de 100km de comprimento, para visualizar rapidamente os dados.
plot(st_geometry(cursos[cursos$NUCOMPCDA > 100, ]), col = "blue", lwd = 0.2)
plot(st_geometry(regioes), add = TRUE)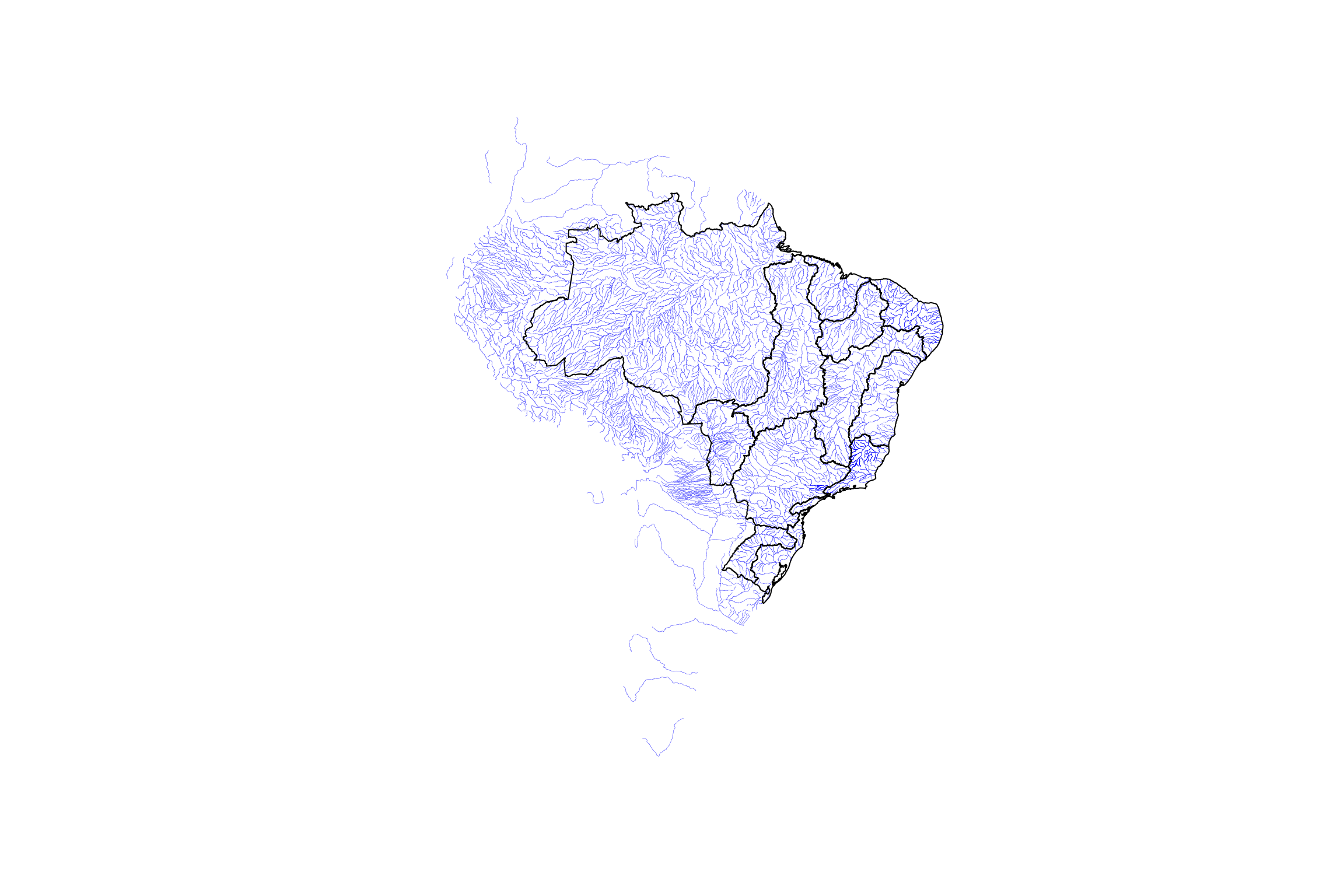
Aí estão os nossos dados: os cursos d’água e os polígonos.
Para concluir a etapa de preparação ainda é preciso identificar a região hidrográfica a que cada rio pertence.
Identificar RHI dos cursos d’água
Conforme comentei acima a base de cursos d’água não identifica a RHI de cada curso. Como o objetivo é colorir os rios de acordo com a região, esta é uma etapa importante do procedimento.
A identificação será feita com uma operação de intersecção. Isto é, perguntarei ao R em qual polígono de região as linhas dos cursos d’água estão. Usando em conjunto as funções st_join() e st_intersects() do pacote sf é possível realizar esta operação. Trabalharei apenas com os cursos d’água com comprimento igual ou maior que 15 km. Além de ser o suficiente para não poluir a visualização, levará menos tempo para processar.
Ainda assim, a intersecção envolverá milhares de cursos d’água e, por isso, esta etapa dura alguns minutos de processamento.
Talvez valha a pena rodar o código e parar para tomar um café. ;)
# Etapa 1
## Identificar RHI de cada cursos d'água
cursos <- cursos %>%
filter(NUCOMPCDA >= 15) %>%
st_join(regioes %>% select(RHI_NM, RHI_CD), join = st_intersects)
head(cursos)A operação realizada no passo anterior adicionou na base de cursos as colunas RHI_CD e RHI_NM e agora sabemos a qual região cada rio pertence.
Mas há erros. A operação era vulnerável a possíveis inconsistências entre as duas bases.
Os limites de bacias hidrográficas são dados pela parte mais alta do relevo, então ao menos em tese um rio não deveria cruzar de uma região hidrográfica para outras. Por inconsistências na geometria das duas bases de dados, há casos em que isso ocorre. Quando uma linha, representando um rio, cruza as bordas de um polígono, ela é identificada como pertencendo a mais de uma região. Estes rios agora estão duplicados na base cursos, com uma região correta e outra errada.
cursos %>% filter(duplicated(COCURSODAG)) %>% dim()## [1] 0 3Eu poderia simplesmente excluir as observações com em que a RHI está errada e deixar apenas aquelas com o valor correto. Mas eu precisaria saber quais rios estão duplicados e quais a regiões corretas de cada um deles e levantar essas informações daria muito trabalho.
Para resolver este problema eu farei uma intersecção dos polígonos com os centroides dos rios duplicados. Provavelmente haverá um outro caso que não será corrigido após este procedimento, mas se forem poucos, não haverá importância, já que nosso objetivo é estético.
# Etapa 2
# identificar e separar cursos duplicados
cod <- cursos %>% filter(duplicated(COCURSODAG)) %>% pull(COCURSODAG)
erros <- cursos %>% filter(COCURSODAG %in% cod)
# identificar RHI dos centroides dos cursos separados
erros_cent <- erros %>%
distinct(COCURSODAG, .keep_all = TRUE) %>%
select(COCURSODAG, NUCOMPCDA) %>%
st_centroid() %>%
st_join(regioes, join = st_intersects)
# limpar geometria
st_geometry(erros_cent) <- NULL
# mesclar em erros
erros <- erros %>%
select(-RHI_NM, -RHI_CD) %>%
merge(erros_cent %>% select(COCURSODAG, RHI_NM, RHI_CD), by = "COCURSODAG", all.x = T) %>%
filter(!duplicated(COCURSODAG))
cursos <- cursos %>%
# Retirar cursos errados e cursos d'água fora do território brasileiro
filter(!(COCURSODAG %in% cod), !is.na(RHI_CD)) %>%
# reunir cursos com RHI corrigida
rbind(erros)head(cursos)## Simple feature collection with 6 features and 4 fields
## geometry type: MULTILINESTRING
## dimension: XY
## bbox: xmin: -2575625 ymin: 7907111 xmax: -617523.6 ymax: 9069233
## epsg (SRID): NA
## proj4string: +proj=utm +zone=23 +south +ellps=GRS80 +units=m +no_defs
## # A tibble: 6 x 5
## COCURSODAG NUCOMPCDA RHI_NM RHI_CD geometry
## <chr> <dbl> <chr> <dbl> <MULTILINESTRING [m]>
## 1 4448 411. AMAZÔN… 1 ((-685345.4 8528286, -685204.7 85289…
## 2 446 774. AMAZÔN… 1 ((-965436.9 8810810, -967588.4 88132…
## 3 4634 904. AMAZÔN… 1 ((-1215932 8539948, -1216812 8539381…
## 4 46362 435. AMAZÔN… 1 ((-1587682 8843464, -1587188 8844405…
## 5 464 1428. AMAZÔN… 1 ((-2480176 8541432, -2479726 8541993…
## 6 4644 1298. <NA> NA ((-1990049 8288375, -1989618 8288919…Restaram na base 32.695 observações. Além do código e do cumprimento do curso d’água, a base agora tem também duas novas variáveis identificando a região hidrográfica, criadas a partir da intersecção com os polígonos das regiões.
Plotar os mapas
Para plotar os mapas eu usarei um fundo preto, mas o ggplot2 não tem nenhum tema embutido assim. Para obter o layout desejado sem repetir código, vou usar a função theme_set() do ggplot2 para definir um tema padrão a partir de dark_map_theme(), que está no pacote seda.
# Definir o tema utilizado na criação dos gráficos
theme_set(
dark_map_theme() +
theme(panel.background = element_rect(fill = 'black', colour = NA),
plot.background = element_rect(fill = "black", colour = NA)) +
theme(legend.position = "none")
)
# criar paleta arco íris
cores <- rainbow(12, s = .4, v = 1)Agora o tema será automaticamente aplicado a todos os gráficos (mapas) gerados a seguir. Eu também já defini uma paleta com 12 cores da escala arco-íris, que serão usadas para colorir as regiões hidrográficas.
cores## [1] "#FF9999FF" "#FFCC99FF" "#FFFF99FF" "#CCFF99FF" "#99FF99FF"
## [6] "#99FFCCFF" "#99FFFFFF" "#99CCFFFF" "#9999FFFF" "#CC99FFFF"
## [11] "#FF99FFFF" "#FF99CCFF"Mapa do Brasil
Agora é parte mais fácil. Com o ggplot2 é relativamente simples plotar objetos simple features.
# criar o mapa do Brasil
ggplot(cursos %>% filter(NUCOMPCDA > 40)) +
geom_sf(aes(colour = RHI_NM, size = NUCOMPCDA, alpha = NUCOMPCDA)) +
scale_colour_manual(values = cores) +
scale_size_continuous(range = c(.1, 1))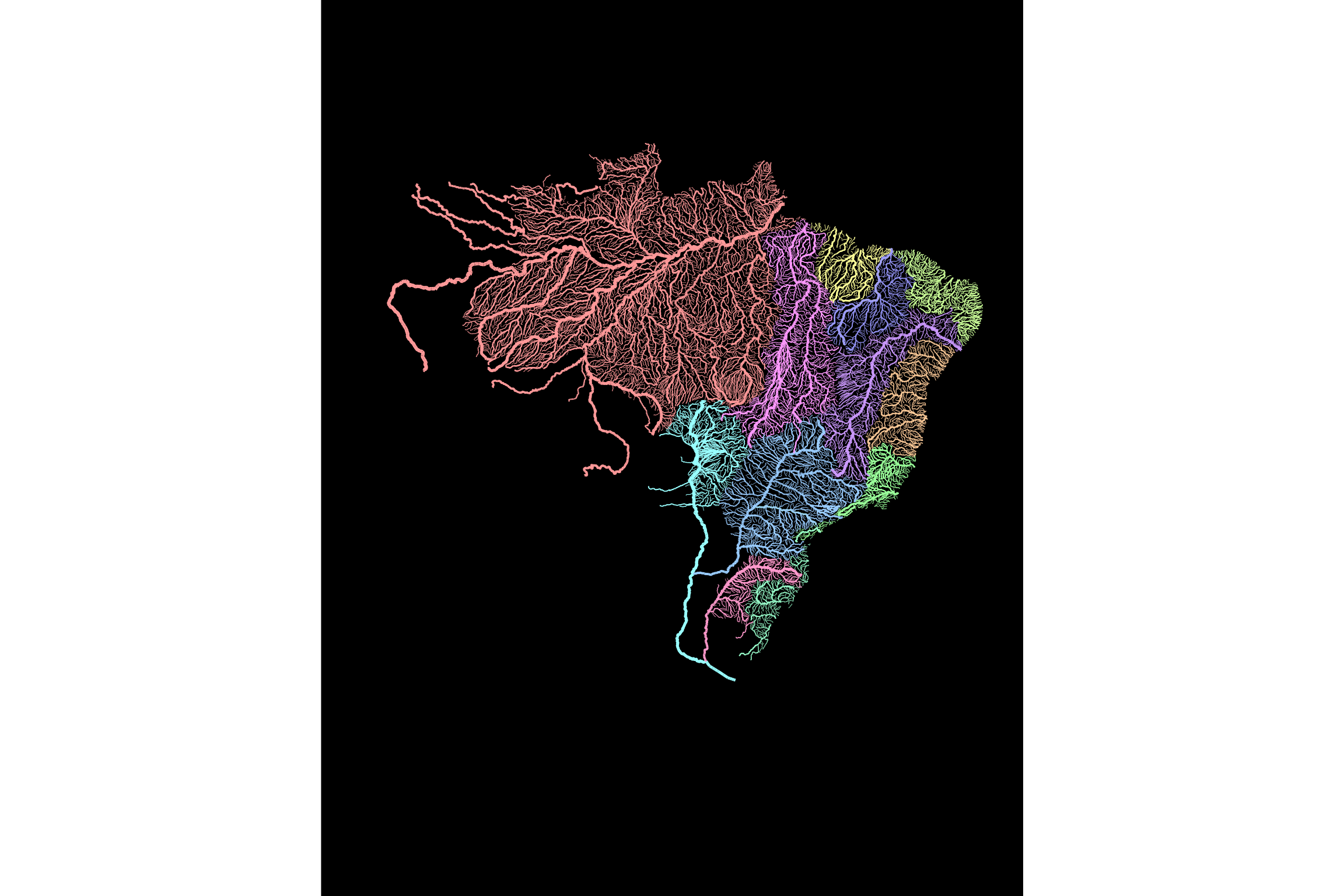
Pronto, isso era tudo o que precisava para criar este bonito mapa hídrico do território brasileiro contendo os cursos d’água com mais de 40 km de comprimento.
Para criar o efeito visual de relevo bastam definir:
a largura e a transparência da linha a partir do comprimento do rio, dado pela variável
NUCOMPCDA.que as linhas deverão ter largura em um intervalo de 0.1 para os menores rios até 1 para os maiores rios (este valor talvez precise ser adequado dependendo da escala dos mapas ou tamanho do arquivo gerado).
Com estas definições, basicamente, quanto maior o rio, mais largo ele é representado e mais visível ele fica.
Mapas das regiões hidrográficas
Já a criação dos mapas das regiões é uma tarefa repetitiva. São 12 mapas.
Para não repetir o código usado acima 12 vezes criei uma função customizada plot_regioes() para replicar o procedimento usando a função map do pacote purr (parte do tidyverse), que é uma alternativa ao lapply()/sapply(). A diferença é que antes de gerar o mapa a função filtrará uma região, usará seu nome no título e aplicará uma das cores da paleta cores.
## Criar os mapas de todas as regiões hidrográficas
plot_regioes <- function(codigo) {
cor <- cores[codigo] # selecionar a cor
regiao <- unique(cursos$RHI_NM[cursos$RHI_CD == codigo]) # selecionar a regiao
return(
ggplot(cursos %>% filter(RHI_CD == codigo)) +
geom_sf(aes(colour = cor, size = NUCOMPCDA, alpha = NUCOMPCDA)) +
scale_colour_manual(values = cor) +
scale_size_continuous(range = c(.1, 1)) +
labs(title = "", subtitle = paste("RHI", str_to_title((regiao))))
)
}Eu agora aplicarei a função plot_regioes em looping, usando a função map.
map(1:12, ~plot_regioes(.))## [[1]]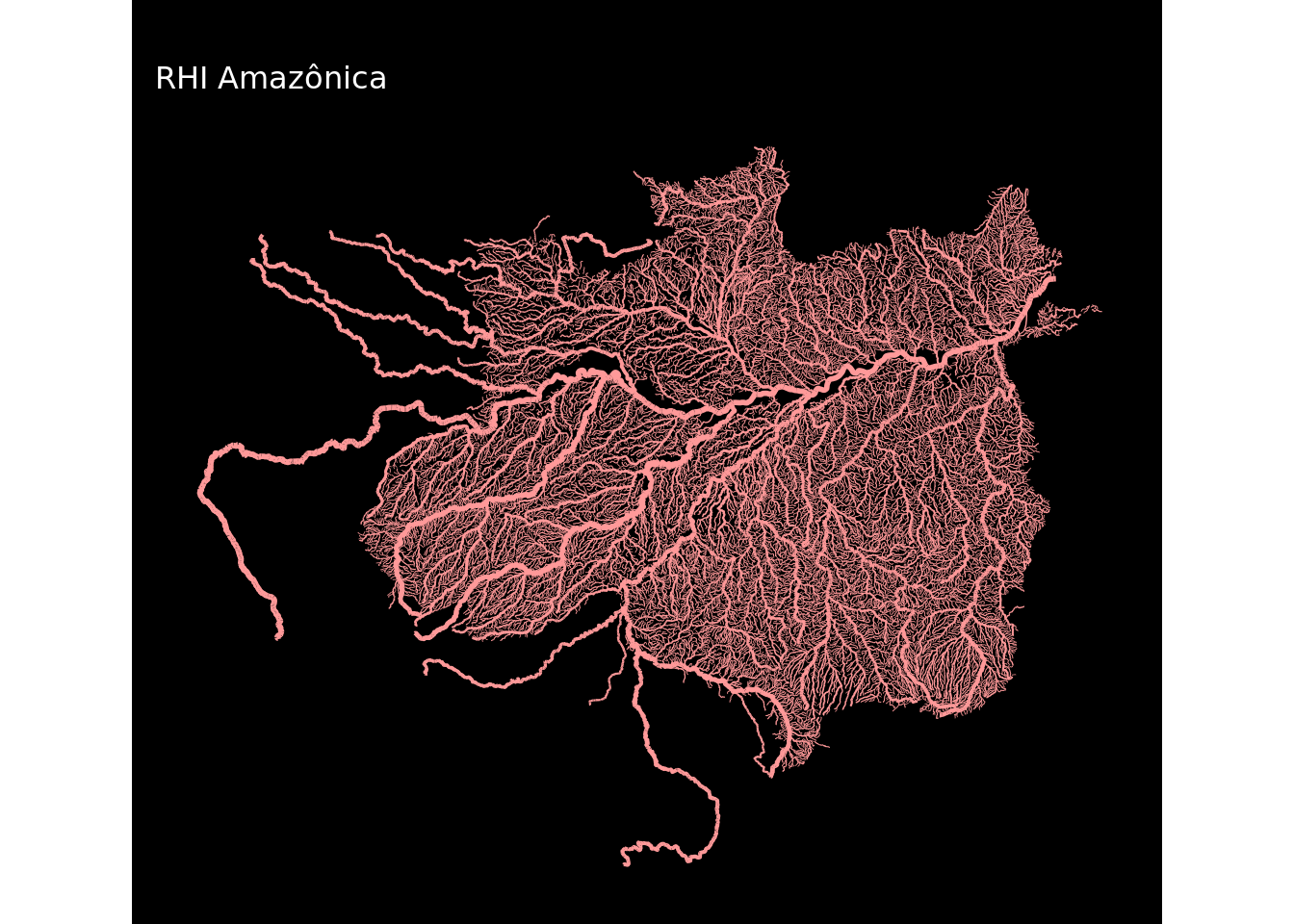
##
## [[2]]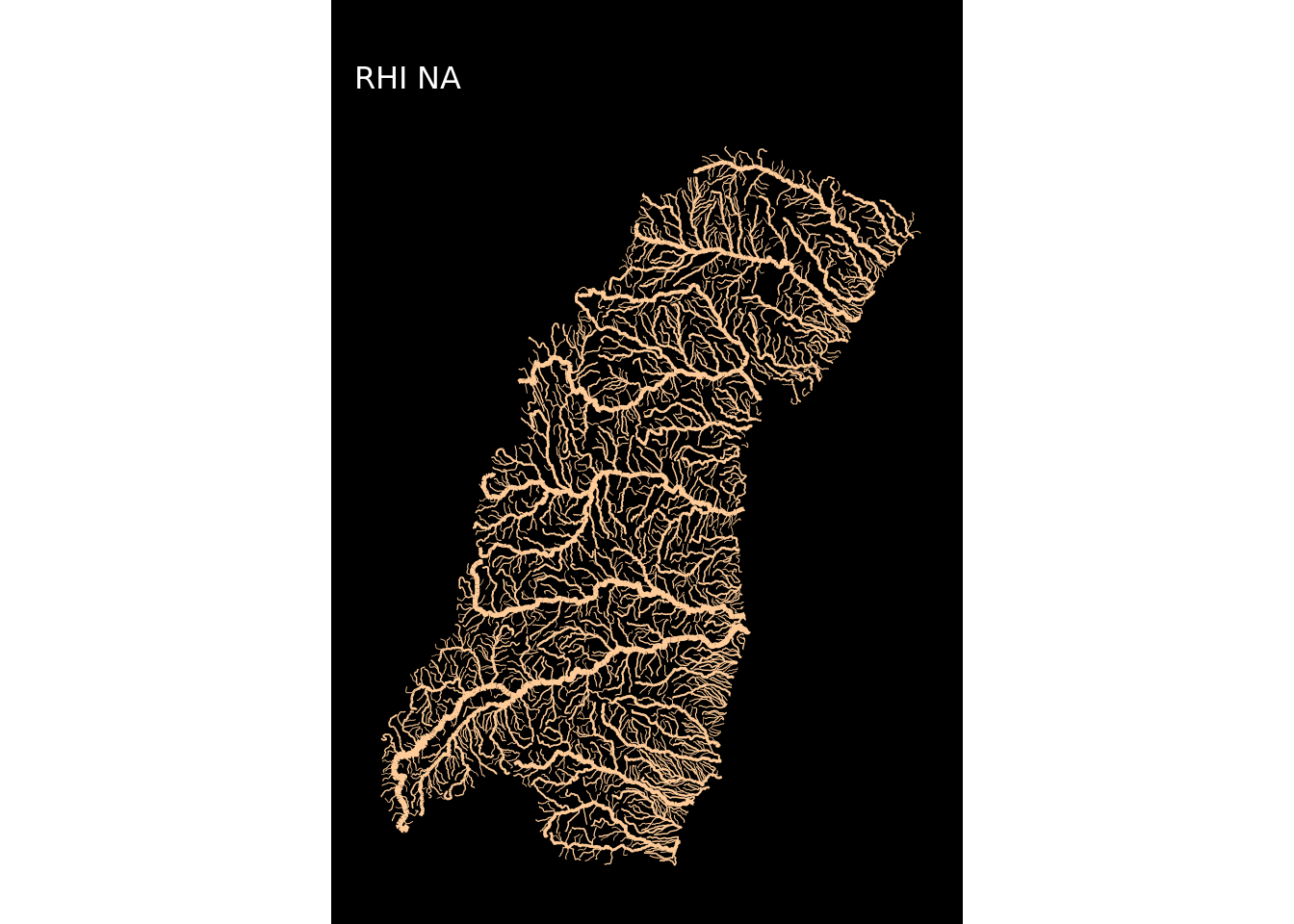
##
## [[3]]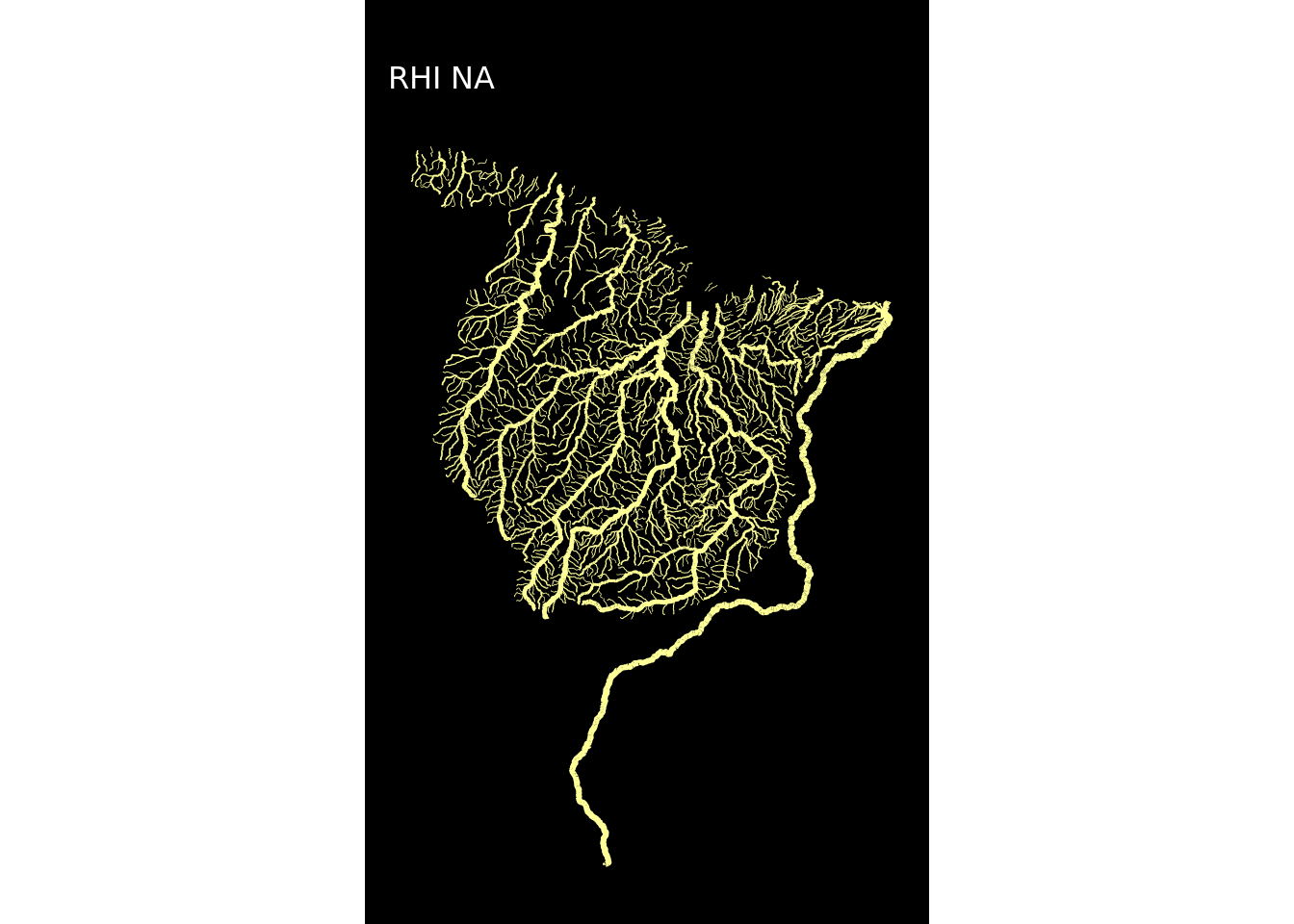
##
## [[4]]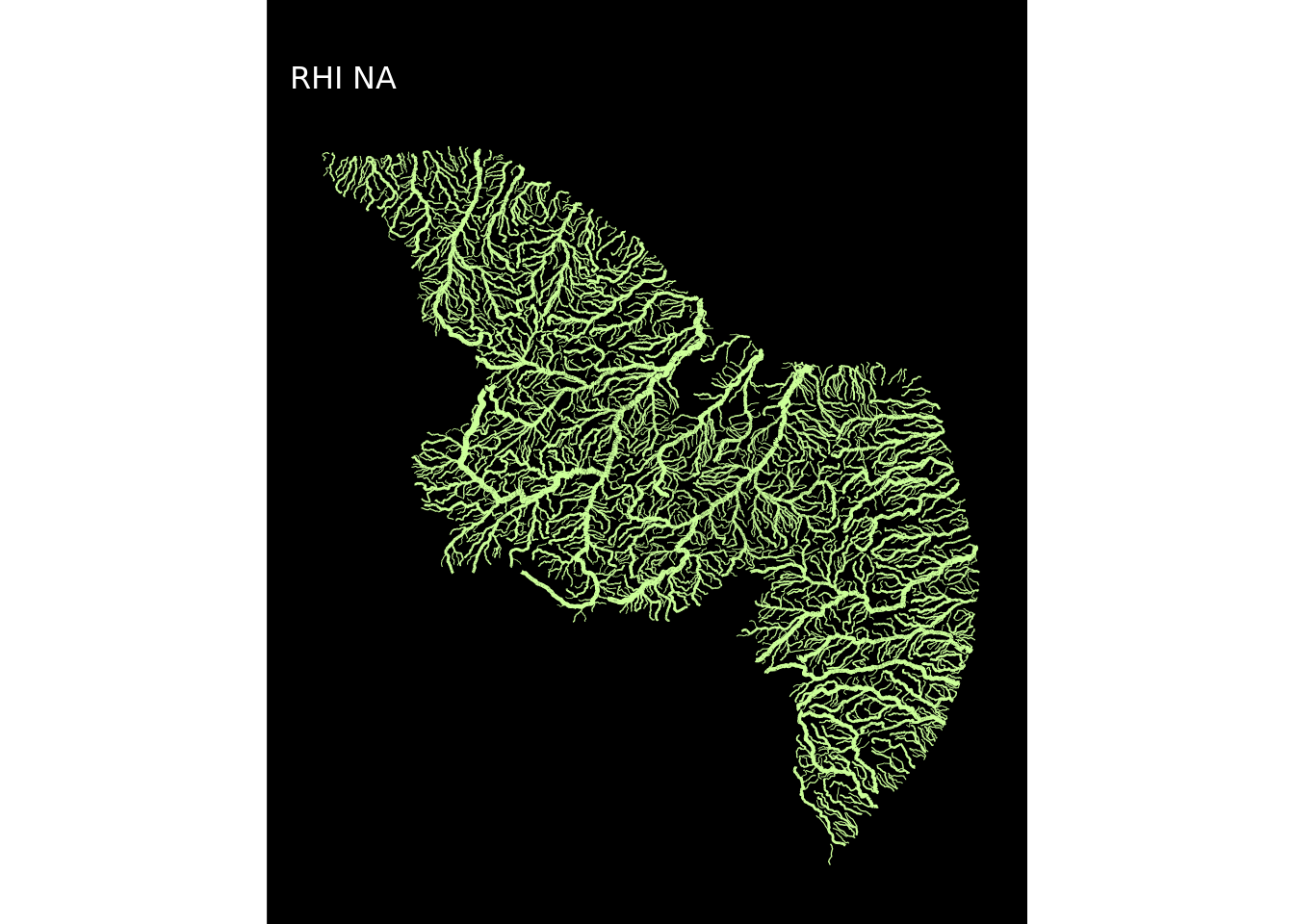
##
## [[5]]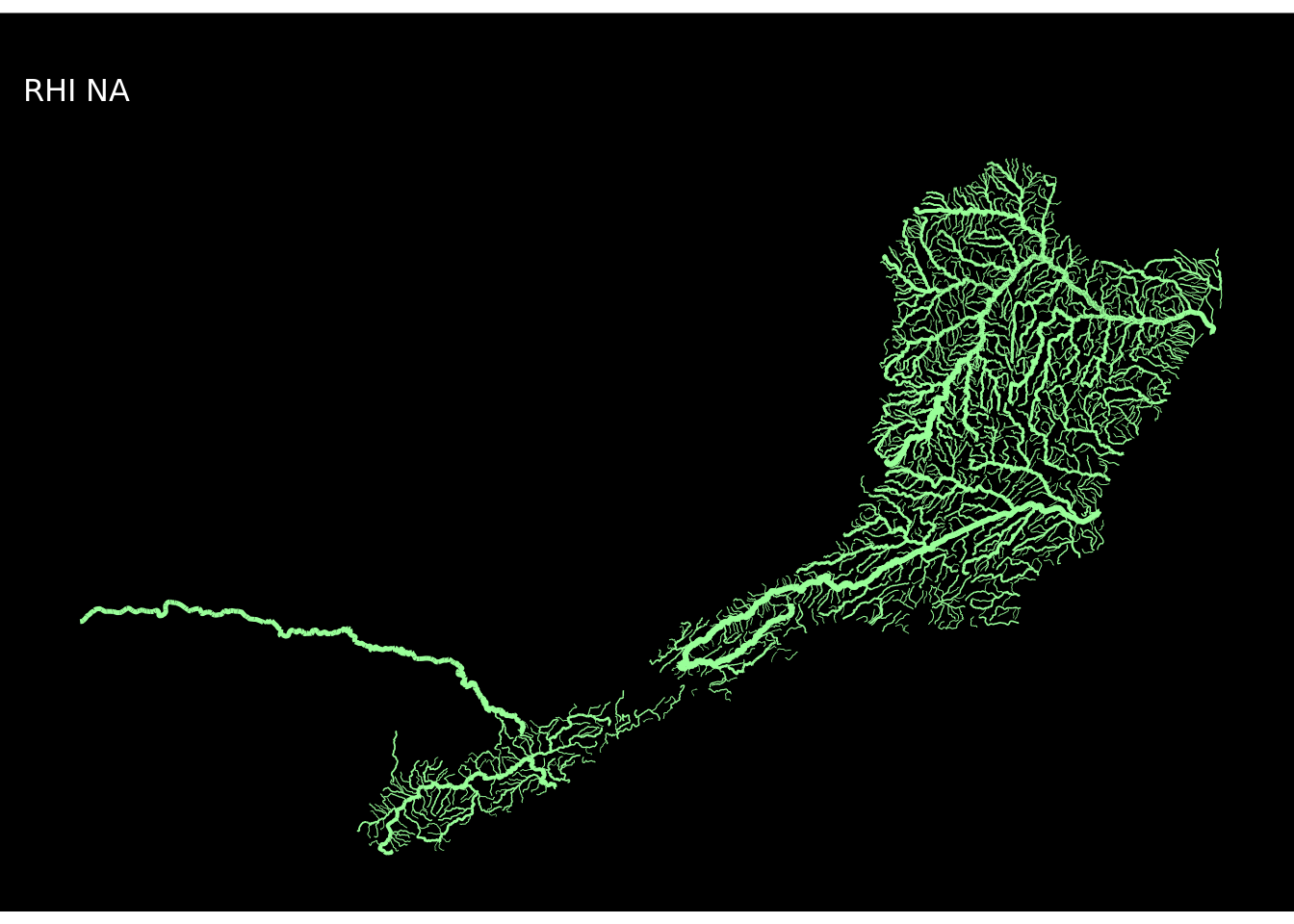
##
## [[6]]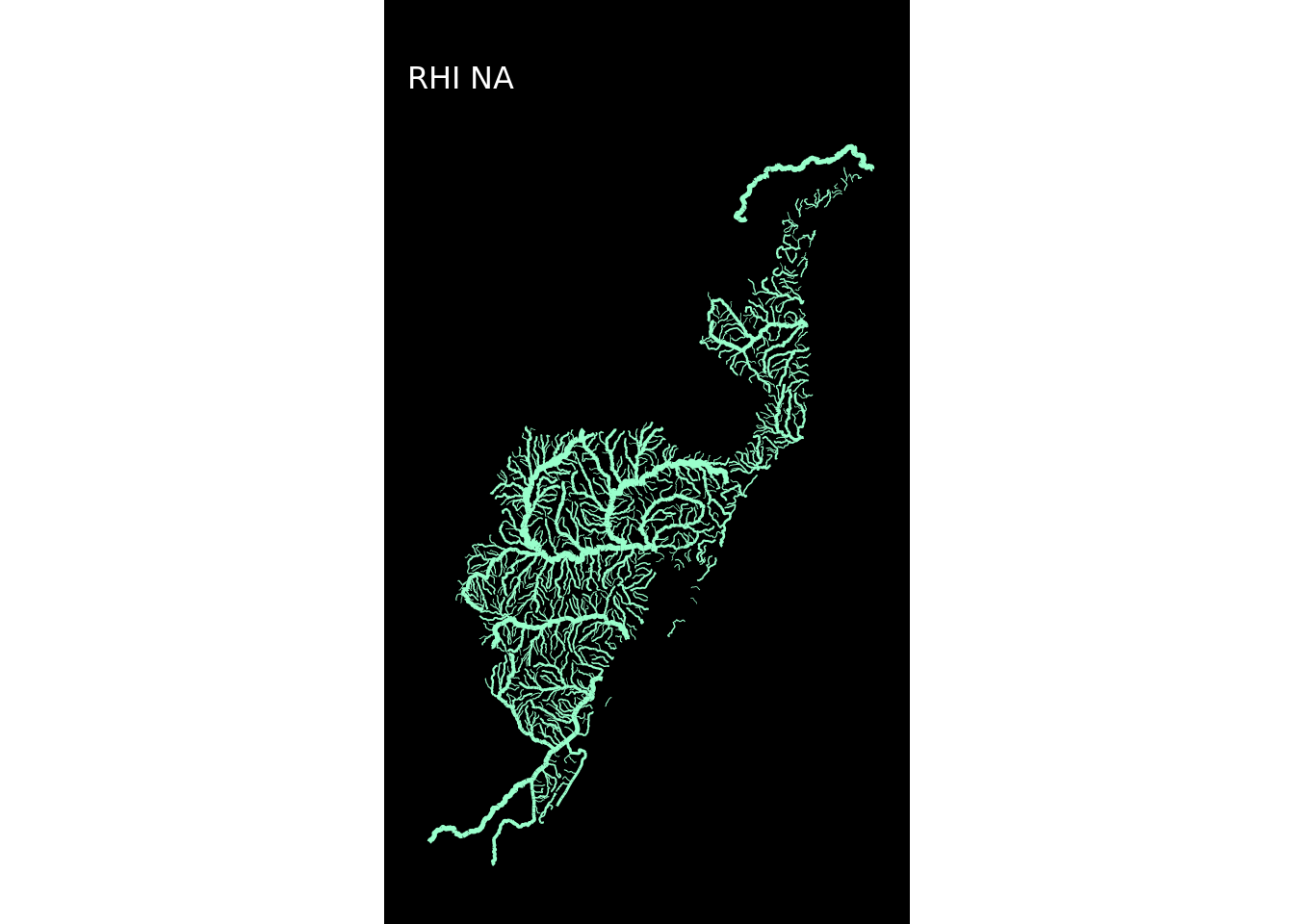
##
## [[7]]
##
## [[8]]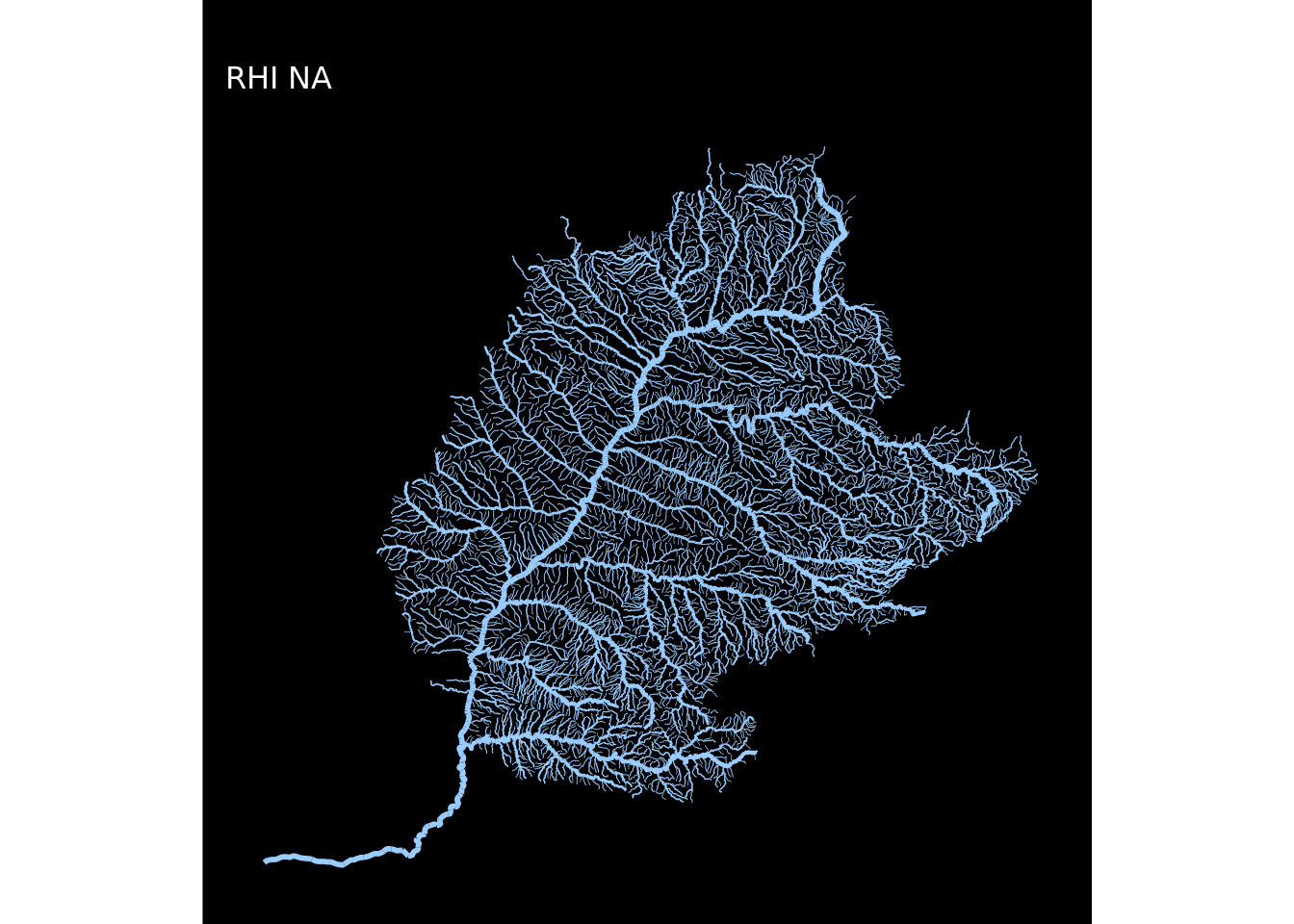
##
## [[9]]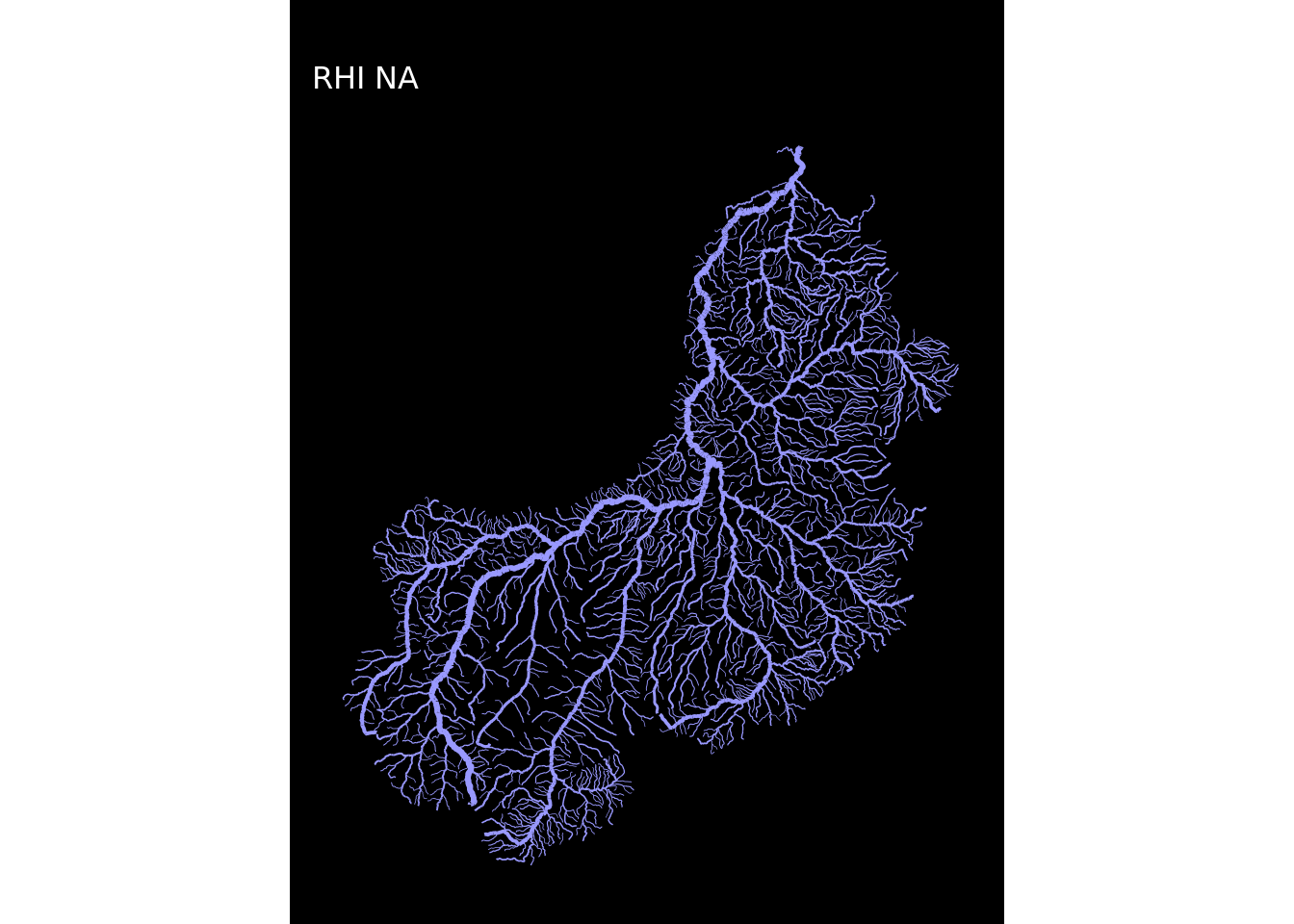
##
## [[10]]
##
## [[11]]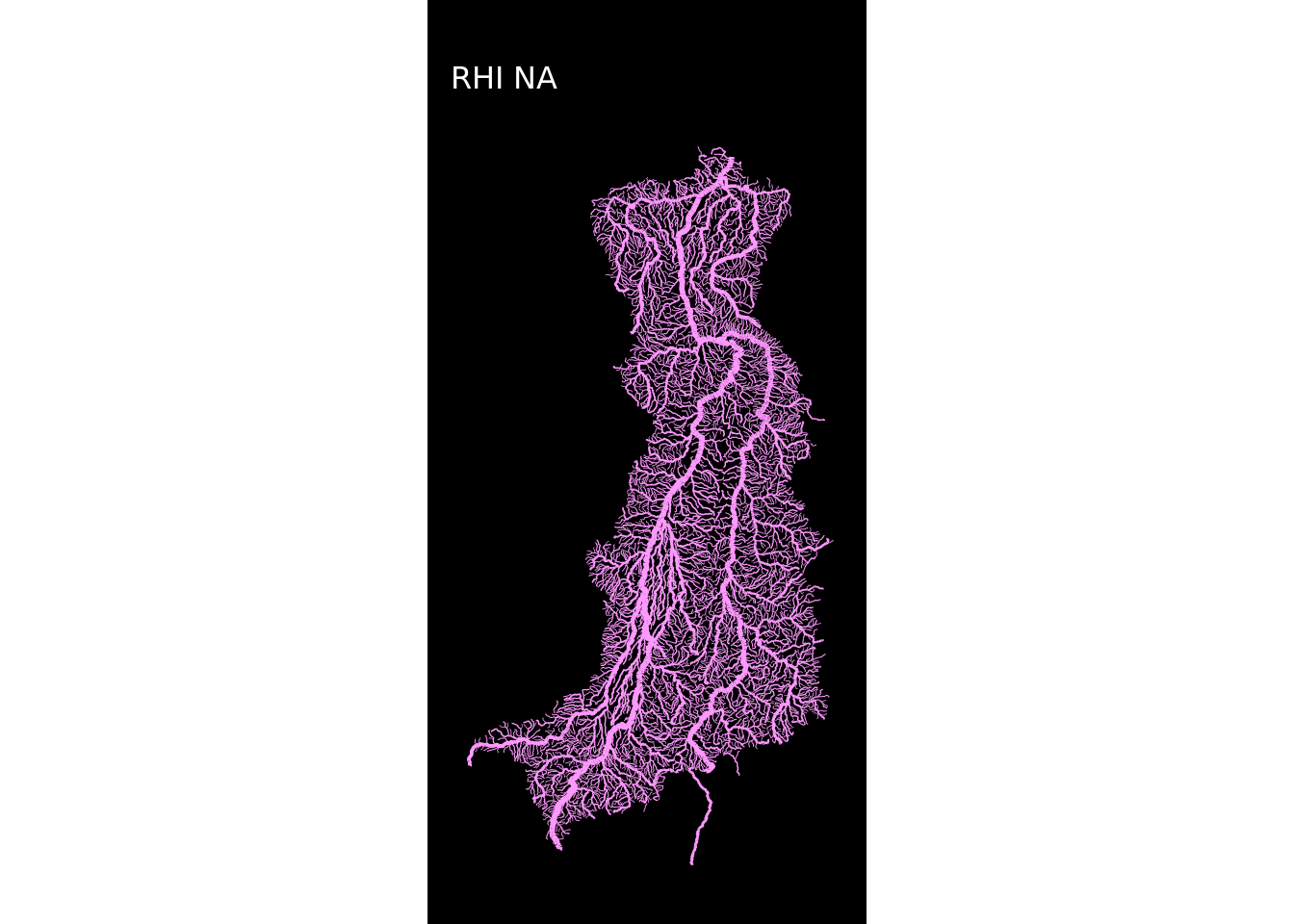
##
## [[12]]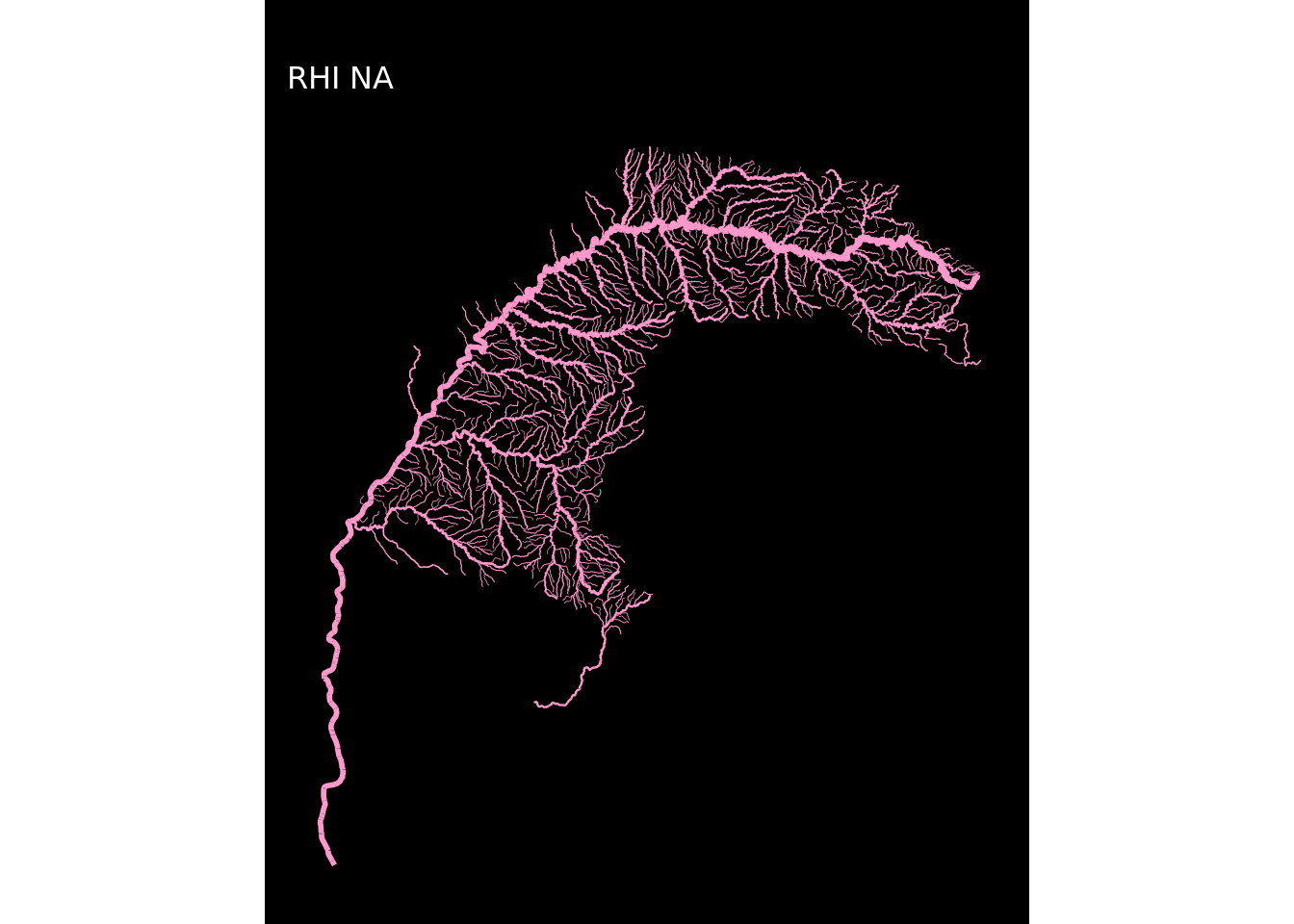
E pronto! Os mapas estão todos criados!
Algumas melhorias poderiam ser feitas, como corrigir a densidade de cursos d’água de algumas regiões, para melhorar o efeito visual. Mas o objetivo aqui é só apresentar o procedimento de produção dos mapas e isso já dá conta.
Espero que este material seja útil para você de alguma forma e, caso tenha dúvidas ou sugestões, deixe seu recado!