O trabalho com mapas raciais feito por Hugo Nicolau e divulgado em seu blog me chamou a atenção para a metodologia conhecida como mapas de pontos de contagem, potente para a análise da densidade de fenômenos.
Ela é usada em uma porção de áreas como epidemiologia, demografia, logística, biologia e tem grande espaço para aplicações no campo das políticas públicas, pois é potente para abordar uma série de problemas, entre eles associações de desigualdade.
Recentemente busquei formas de reproduzir o trabalho do Hugo no R e, fortunamente, encontrei que é na verdade um procedimento relativamente simples. Neste post vou compartilhar como construir mapas de ponto de contagens no R em base tidy, criando mapas da cidade de Peruíbe, no litoral sul de São Paulo.
Para isto utilizarei os pacotes sf para manipular os dados espaciais e o ggplot2 para gerar os mapas. Além disso, farei uso também de funções criadas por mim, agrupadas por hora no pacote seda, para obter os dados do IBGE.
Mapas de pontos de contagem
Criar um mapa de pontos é simples quando você já tem o layer de pontos. O que esta metodologia propõe é recriar representações espaciais dadas por polígonos em representações espaciais dadas por pontos, baseadas nas informações associadas aos polígonos.
A ideia é simples: cada ponto representará uma quantidade n de observações (ex.: um ponto para cada indivíduo, para cada 10 etc) e eles serão distribuídos aleatoriamente dentro de polígonos espaciais aos quais estão associados.
Exemplo. Quando faz o Censo o IBGE registra dados demográficos e socioeconômicos de toda a população brasileira e cada pessoa é registrada no setor censitário de sua residência. O setores censitários são pequenas porções territoriais contíguas utlizadas para fins cadastrais e constituem a unidade básica de desagregação espacial do Censo.
Com estes dados construir um mapa de pontos significa distribuir aleatoriamente pontos representando pessoas em seus respectivos setores censitários.
Passo 1: obter os dados
A ideia é criar um mapa que permita analisar a associação espacial entre raça e renda dentro dos limites da cidade de Peruíbe.
O procedimento envolve especificamente variáveis de raça e renda dos resultados do universo do Censo 2010. Estes dados estão disponíveis no ftp do IBGE e no seu geoftp.
Os dados demográficos fazem parte dos resultados do universo e os dados espaciais, isto é, os polígonos dos setores censitários, integram o conjunto de dados sobre malhas territoriais.
Obter dados do IBGE, embora fácil, é uma tarefa dispendiosa. São muitos arquivos, é muito pesado para guardar tudo (além de desnecessário já que o IBGE já faz o serviço de armazená-los) e quem trabalha com estes dados vira e mexe precisa novamente baixá-los.
Para facilitar esta tarefa eu criei algumas funções que facilitam a obtenção dos dados do IBGE diretamente no R, particularmente os dos resultados do universo e os dados espaciais. Elas fazem parte de um pacote chamado seda. Para construir os mapas não é necessário instalá-lo, basta ter os dados e você pode obtê-los nos links acima. Mas se você preferir seguir pelo caminho mais fácil:
# para instalar o pacote seda
devtools::install_github("bruno-pinheiro/seda")Obs.: o pacote seda foi testado apenas em linux Debian 9
# carregar pacotes
library(seda)
library(sf)
library(dplyr)
library(tidyr)
library(ggplot2)
library(gridExtra)
library(data.table)Quero a malha de setores censitários e as seguintes variáveis populacionais:
- número de habitantes nos setores censitários por raça
- número de habitantes nos setores censitários por classe social
Como a análise envolve renda, trabalharei apenas com dados a respeito de pessoas com 10 anos ou mais, já que esta é a faixa etária a partir do qual o IBGE passa a coletar informações de rendimento.
Usando o pacote seda vou baixar e importar o shapefile de setores censitários do estado de São Paulo. Esta etapa demorará um pouco, pois os dados são pesados. Dependendo da sua conexão, dá tempo de pegar (ou tomar) um café.
# malha de setores
url <- "ftp://geoftp.ibge.gov.br/organizacao_do_territorio/malhas_territoriais/malhas_de_setores_censitarios__divisoes_intramunicipais/censo_2010/setores_censitarios_shp/sp/sp_setores_censitarios.zip"
get_ibge(url)
# dados tabulares
url <- "ftp://ftp.ibge.gov.br/Censos/Censo_Demografico_2010/Resultados_do_Universo/Agregados_por_Setores_Censitarios/SP_Exceto_a_Capital_20190207.zip"
get_ibge(url)
rm(url)Os arquivos foram baixados na pasta temporária e preciso saber seus nomes para importar no R.
Vou então buscar o nome do shapefile…
#listar arquivo .shp
list_tmp("shp")## [1] "/tmp/RtmpKLDLtK/33SEE250GC_SIR.shp"e listar os arquivos em formato .csv que foram baixados.
# listar arquivos .csv
list_tmp("csv")## [1] "/tmp/RtmpKLDLtK/Basico_SP2.csv"
## [2] "/tmp/RtmpKLDLtK/Domicilio01_SP2.csv"
## [3] "/tmp/RtmpKLDLtK/Domicilio02_SP2.csv"
## [4] "/tmp/RtmpKLDLtK/DomicilioRenda_SP2.csv"
## [5] "/tmp/RtmpKLDLtK/Entorno01_SP2.csv"
## [6] "/tmp/RtmpKLDLtK/Entorno02_SP2.csv"
## [7] "/tmp/RtmpKLDLtK/Entorno03_SP2.csv"
## [8] "/tmp/RtmpKLDLtK/Entorno04_SP2.csv"
## [9] "/tmp/RtmpKLDLtK/Entorno05_SP2.csv"
## [10] "/tmp/RtmpKLDLtK/Pessoa01_SP.csv"
## [11] "/tmp/RtmpKLDLtK/Pessoa02_SP.csv"
## [12] "/tmp/RtmpKLDLtK/Pessoa03_SP.csv"
## [13] "/tmp/RtmpKLDLtK/Pessoa04_SP.csv"
## [14] "/tmp/RtmpKLDLtK/Pessoa05_SP.csv"
## [15] "/tmp/RtmpKLDLtK/Pessoa06_SP.csv"
## [16] "/tmp/RtmpKLDLtK/Pessoa07_SP.csv"
## [17] "/tmp/RtmpKLDLtK/Pessoa08_SP.csv"
## [18] "/tmp/RtmpKLDLtK/Pessoa09_SP.csv"
## [19] "/tmp/RtmpKLDLtK/Pessoa10_SP.csv"
## [20] "/tmp/RtmpKLDLtK/Pessoa11_SP.csv"
## [21] "/tmp/RtmpKLDLtK/Pessoa12_SP.csv"
## [22] "/tmp/RtmpKLDLtK/Pessoa13_SP.csv"
## [23] "/tmp/RtmpKLDLtK/PessoaRenda_SP2.csv"
## [24] "/tmp/RtmpKLDLtK/responsavel01_sp2.csv"
## [25] "/tmp/RtmpKLDLtK/responsavel02_sp2.csv"
## [26] "/tmp/RtmpKLDLtK/ResponsavelRenda_SP2.csv"Pronto. O shapefile está nomeado como “35SEE250GC_SIR.shp” e as variáveis tabulares de interesse estão nos seguintes arquivos (sim, é preciso ler o dicionário de variáveis):
Pessoa03_SP.csv- raça: V002:V006
Pessoa11_SP.csvePessoa12_SP.csv:- sexo: V001
PessoaRenda_SP.csv:- renda: V001 a V009 (excluindo pessoas sem rendimento)
Então já posso importar os dados:
# importar dados em lista
camadas <- list(
# raca
raca = fread(list_tmp("Pessoa03_SP.csv"),
sep = ";", encoding = "Latin-1") %>%
select(Cod_setor, V002:V006),
# renda
renda = fread(list_tmp("PessoaRenda_SP2.csv"),
sep = ";", encoding = "Latin-1") %>%
select(Cod_setor, V001:V009),
# setores censitários
setores = read_sf(dsn=list_tmp("shp"), options = "ENCODING=Latin1")
)
camadas## $raca
## Cod_setor V002 V003 V004 V005 V006
## 1: 350010505000001 249 3 28 24 0
## 2: 350010505000002 550 13 86 136 0
## 3: 350010505000003 432 3 65 24 0
## 4: 350010505000004 613 8 63 111 0
## 5: 350010505000005 744 4 31 33 1
## ---
## 47729: 355730305000008 608 24 11 172 0
## 47730: 355730305000009 45 0 0 12 0
## 47731: 355730305000010 89 2 0 10 2
## 47732: 355730305000011 697 59 0 232 0
## 47733: 355730305000012 727 33 1 284 0
##
## $renda
## Cod_setor V001 V002 V003 V004 V005 V006 V007 V008 V009
## 1: 350010505000001 0 43 63 33 47 34 4 3 4
## 2: 350010505000002 10 135 168 78 83 56 10 9 2
## 3: 350010505000003 0 57 94 45 79 61 16 22 3
## 4: 350010505000004 8 122 125 78 83 88 16 10 12
## 5: 350010505000005 5 133 179 74 98 55 5 8 7
## ---
## 47729: 355730305000008 24 76 163 73 40 18 1 0 0
## 47730: 355730305000009 2 4 13 4 5 2 0 0 0
## 47731: 355730305000010 1 16 23 7 8 3 0 0 0
## 47732: 355730305000011 34 122 224 94 48 11 0 0 0
## 47733: 355730305000012 23 195 215 62 44 8 1 0 0
##
## $setores
## Simple feature collection with 68296 features and 14 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -53.11011 ymin: -25.31232 xmax: -44.16137 ymax: -19.77966
## epsg (SRID): 4674
## proj4string: +proj=longlat +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +no_defs
## # A tibble: 68,296 x 15
## ID CD_GEOCODI TIPO CD_GEOCODS NM_SUBDIST CD_GEOCODD NM_DISTRIT
## <dbl> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 98237 354100005… URBA… 354100005… <NA> 354100005 PRAIA GRA…
## 2 98232 354100005… URBA… 354100005… <NA> 354100005 PRAIA GRA…
## 3 98230 354100005… URBA… 354100005… <NA> 354100005 PRAIA GRA…
## 4 98229 354100005… URBA… 354100005… <NA> 354100005 PRAIA GRA…
## 5 98231 354100005… URBA… 354100005… <NA> 354100005 PRAIA GRA…
## 6 98233 354100005… URBA… 354100005… <NA> 354100005 PRAIA GRA…
## 7 98236 354100005… URBA… 354100005… <NA> 354100005 PRAIA GRA…
## 8 98242 354100005… URBA… 354100005… <NA> 354100005 PRAIA GRA…
## 9 98239 354100005… URBA… 354100005… <NA> 354100005 PRAIA GRA…
## 10 98238 354100005… URBA… 354100005… <NA> 354100005 PRAIA GRA…
## # … with 68,286 more rows, and 8 more variables: CD_GEOCODM <chr>,
## # NM_MUNICIP <chr>, NM_MICRO <chr>, NM_MESO <chr>, CD_GEOCODB <chr>,
## # NM_BAIRRO <chr>, ID1 <dbl>, geometry <MULTIPOLYGON [°]>Como resultado cada uma das três bases é um elemento dentro da lista camadas.
O shapefile contem os polígonos dos setores censitários e as duas bases tabulates contém informações sobre raça e renda dos habitantes dos 68296 setores censitários do estado de São Paulo, embora eu queira apenas os de Peruíbe.
O próximo passo é preparar os dados.
Passo 2: preparar os dados
Farei o filtro e a limpeza das observações e variáveis que não serão utilizadas, além dos tratamentos necessários. Ao fim quero ter as seguintes variáveis na base de setores censitários:
- raca: brancos, pretos, amarelos, pardos, indigenas
- renda: sm10mais, sm10, sm5, sm2, sm1
Com relação à renda, vale destacar que as faixas de renda são baseadas em salários mínimos e que em 2010 o salário mínimo era de R$ 510. Especificamente, as faixas de renda serão:
- sm10mais: > 10 salários mínimos
- sm10: 5 a 10 salários mínimos
- sm5: 2 a 5 salários mínimos
- sm2: 1 a 2 salários mínimos
- sm1: até 1 salário mínimo
# filtrar setores censitários de Peruíbe
camadas$setores <- camadas$setores %>%
filter(NM_MUNICIP == "PERUÍBE") %>%
select(CD_GEOCODI)
# manipular variáveis de raça e renda
camadas$raca <- camadas$raca %>%
mutate(Cod_setor = as.character(Cod_setor)) %>%
filter(Cod_setor %in% camadas$setores$CD_GEOCODI) %>%
mutate_at(vars(-Cod_setor), as.numeric) %>%
rename(CD_GEOCODI = Cod_setor, brancos = V002, pretos = V003,
amarelos = V004, pardos = V005, indigenas = V006)
camadas$renda <- camadas$renda %>%
mutate(Cod_setor = as.character(Cod_setor)) %>%
filter(Cod_setor %in% camadas$setores$CD_GEOCODI) %>%
mutate_at(vars(-Cod_setor), as.numeric) %>%
mutate(sm1 = V001 + V002,
sm5 = V004 + V005,
sm10mais = V007 + V008 + V009) %>%
select(CD_GEOCODI = Cod_setor, sm10mais, sm10 = V006,
sm5, sm2 = V003, sm1)
# mesclar dados de raça e renda na malha de setores
camadas$setores <- camadas$setores %>%
select(CD_GEOCODI) %>%
left_join(camadas$raca, by = "CD_GEOCODI") %>%
left_join(camadas$renda, by = "CD_GEOCODI") %>%
arrange(CD_GEOCODI) %>%
st_transform(31983) %>%
select(1, 3:12, 2)
# checar dados
glimpse(camadas$setores)## Observations: 130
## Variables: 12
## $ CD_GEOCODI <chr> "353760205000001", "353760205000002", "35376020500000…
## $ brancos <dbl> 424, 154, 125, 333, 267, 268, 257, 338, 448, 434, 205…
## $ pretos <dbl> 5, 5, 1, 13, 9, 26, 13, 12, 10, 4, 1, 3, 6, 10, 68, 1…
## $ amarelos <dbl> 31, 2, 33, 17, 27, 15, 10, 17, 23, 8, 5, 0, 1, 34, 14…
## $ pardos <dbl> 33, 41, 7, 82, 86, 110, 31, 81, 87, 41, 23, 7, 1, 29,…
## $ indigenas <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 2, 0, 0, 3,…
## $ sm10mais <dbl> 24, 4, 4, 6, 9, 1, 6, 10, 12, 10, 15, 2, 2, 18, 2, 2,…
## $ sm10 <dbl> 51, 23, 8, 27, 21, 8, 17, 35, 47, 43, 29, 5, 6, 38, 4…
## $ sm5 <dbl> 139, 44, 35, 92, 66, 55, 61, 119, 146, 85, 38, 18, 13…
## $ sm2 <dbl> 75, 41, 32, 116, 72, 77, 76, 78, 94, 85, 41, 8, 8, 88…
## $ sm1 <dbl> 55, 26, 19, 11, 72, 82, 36, 47, 60, 55, 31, 2, 2, 19,…
## $ geometry <MULTIPOLYGON [m]> MULTIPOLYGON (((297326.1 73..., MULTIPOL…Aí está a variável de identificação do setor censitário reunida às 10 variáveis que indicam o número de pessoas de cada grupo populacional em cada setor censitário.
Visualizar
E assim estão os dados até este instante.
plot(camadas$setores[, 2:6],
key.pos = 1,
key.width = lcm(1.3),
key.length = 1.0,
title = "Distribuição da população pela cidade, por raça")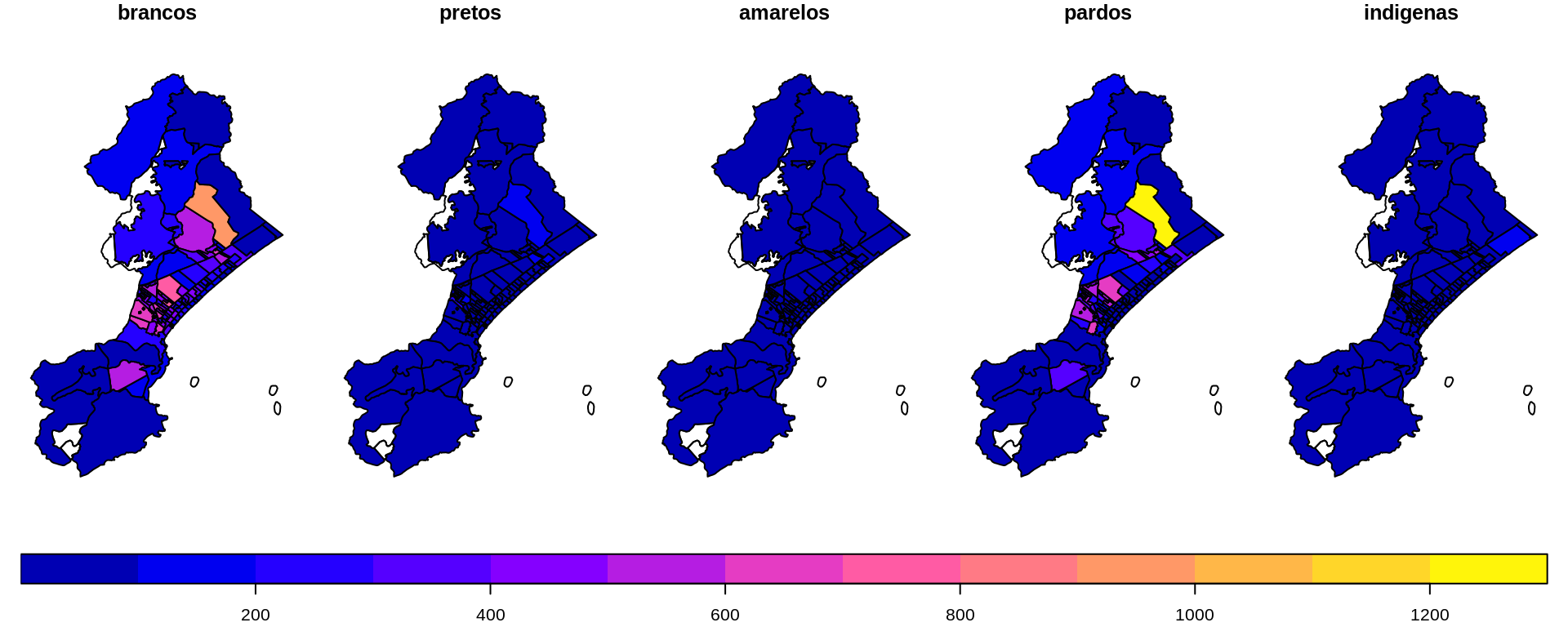
plot(camadas$setores[, 7:11],
key.pos = 1,
key.width = lcm(1.3),
key.length = 1.0,
main = "Distribuição da população pela cidade, por nível de renda")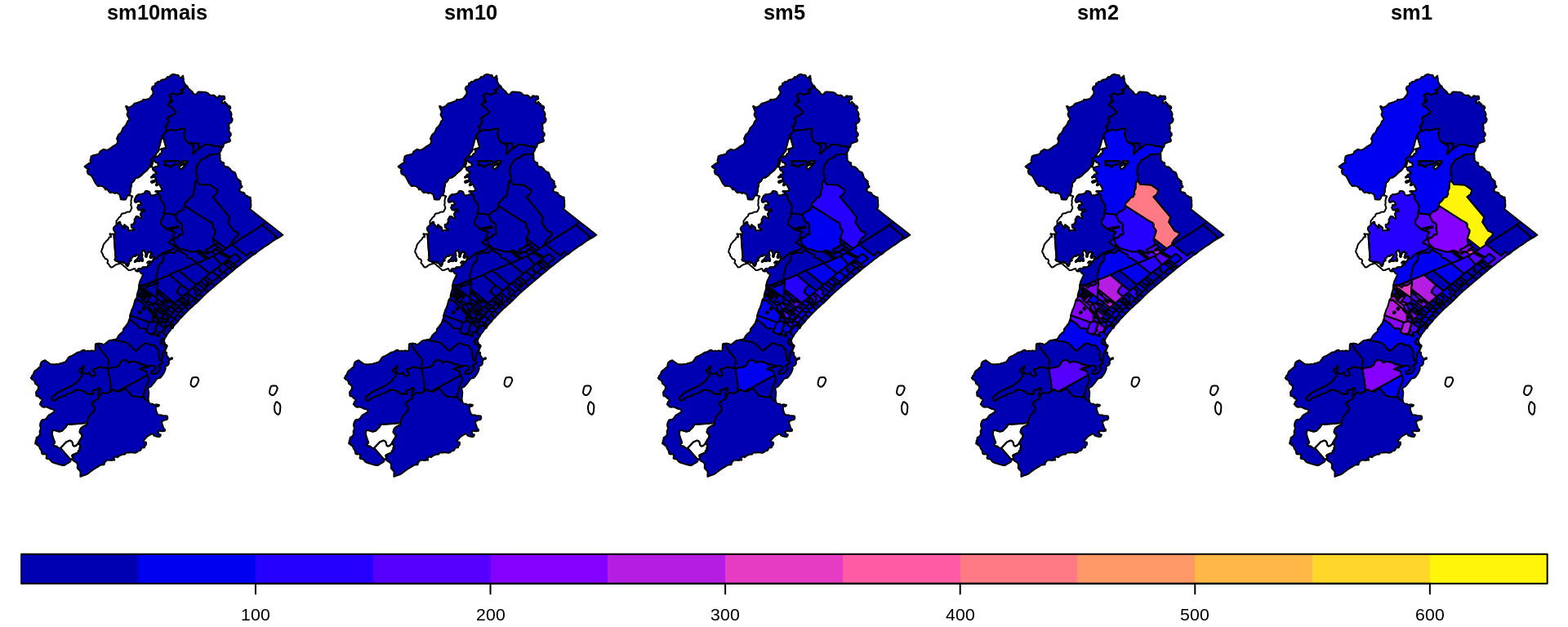
Passo 3: Processamento espacial
Entendendo o procedimento
Uma forma bastante simples de realizar a atribuição espacial aleatória de pontos no R é com a função st_sample() do pacote sf. O que a função faz é pegar um argumento numérico associado a um polígono, que especifique o número de pontos a serem criados, e atribuir aleatoriamente o número determinado de pontos dentro deste polígono.
Este número determinado de pontos \(n\) é dado a partir de uma razão \(b\) do número de habitantes dos grupos populacionais nos setores censitários \(k_{mi}\), em que \(k\) é o número de habitantes, \(m\) é o grupo populacional e \(i\) é o setor censitário. Ou seja, é simples como:
\[n_{mi} = \frac{k_{mi}}{b}\]
São mais de 60 mil habitantes, o que geraria uma sobreposição desnecessária no mapa. Por isso vamos reduzir esta densidade em uma razão \(b = 5\), isto é, um ponto para cada 5 pessoas.
Atribuição aleatória dos pontos
Para realizar a atribuição aleatória dos pontos é preciso tratar os valores ausentes, pois a função st_sample() precisa do número de pontos a serem atribuídos para cada setor. Se não há o número de pessoas indíginas em um setor, por exemplo, a função falhará.
Além de distribuir aleatoriamente os pontos nos setores censitários, eu quero:
- realizar a itersecção entre os pontos e os polígonos, para identificar em qual setor cada ponto está
- criar uma variável indicando o grupo populacional que os pontos representam
E por fim reagruparei os pontos representando a distribuição espacial da população por raça e aqueles que representam a distribuição por renda.
É necessário repetir este procedimento para cada um dos grupos, isto é, 10 vezes. Aplicando a função lapply() o processo é feito em looping, os objetos são estocando numa lista e evita-se repetição de código.
# separar dados missing
nas <- camadas$setores[is.na(camadas$setores$brancos), ]
camadas$setores <- camadas$setores[!is.na(camadas$setores$brancos), ]
# separar nomes das variáveis
variaveis <- names(as_tibble(camadas$setores)[, 2:11])
grupos <- c("Brancos", "Pretos", "Amarelos", "Pardos", "Indígenas",
"SM10+", "SM10", "SM5", "SM2", "SM1")# realizar a atribuição dos pontos para cada grupo populacional
pontos <- lapply(1:10, function(i) {
n_pontos <- round(camadas$setores[, variaveis[i]][[variaveis[i]]] / 5)
st_sample(camadas$setores, n_pontos) %>%
st_sf() %>%
st_join(camadas$setores %>% select(CD_GEOCODI), join = st_intersects) %>%
mutate(categoria = grupos[i])
})
# unir grupos de faixa e renda
# e reunir setores censitários
camadas <- list(
raca = do.call(rbind, pontos[(1:5)]),
renda = do.call(rbind, pontos[6:10]),
setores = rbind(camadas$setores, nas)
)
rm(nas, pontos, v)
camadas## $raca
## Simple feature collection with 12143 features and 2 fields
## geometry type: POINT
## dimension: XY
## bbox: xmin: 285506.8 ymin: 7296119 xmax: 306999.6 ymax: 7330336
## epsg (SRID): 31983
## proj4string: +proj=utm +zone=23 +south +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs
## First 10 features:
## CD_GEOCODI categoria geometry
## 1 353760205000001 Brancos POINT (297338.7 7308979)
## 2 353760205000001 Brancos POINT (297189.5 7308866)
## 3 353760205000001 Brancos POINT (297342 7309266)
## 4 353760205000001 Brancos POINT (297296.6 7308687)
## 5 353760205000001 Brancos POINT (297431.4 7308865)
## 6 353760205000001 Brancos POINT (297464.4 7309003)
## 7 353760205000001 Brancos POINT (297239.7 7308718)
## 8 353760205000001 Brancos POINT (297293.7 7308970)
## 9 353760205000001 Brancos POINT (297202.3 7308733)
## 10 353760205000001 Brancos POINT (297200.3 7308801)
##
## $renda
## Simple feature collection with 6298 features and 2 fields
## geometry type: POINT
## dimension: XY
## bbox: xmin: 286772.5 ymin: 7295890 xmax: 307072.9 ymax: 7329798
## epsg (SRID): 31983
## proj4string: +proj=utm +zone=23 +south +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs
## First 10 features:
## CD_GEOCODI categoria geometry
## 1 353760205000001 SM10+ POINT (297563.8 7309047)
## 2 353760205000001 SM10+ POINT (297382 7309077)
## 3 353760205000001 SM10+ POINT (297466.1 7309034)
## 4 353760205000001 SM10+ POINT (297591.4 7308966)
## 5 353760205000001 SM10+ POINT (297200.5 7308869)
## 6 353760205000002 SM10+ POINT (297640.5 7308876)
## 7 353760205000003 SM10+ POINT (297365.5 7308650)
## 8 353760205000004 SM10+ POINT (296840.9 7308670)
## 9 353760205000005 SM10+ POINT (296772.6 7308932)
## 10 353760205000005 SM10+ POINT (296699.7 7308775)
##
## $setores
## Simple feature collection with 130 features and 11 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: 284871.1 ymin: 7294947 xmax: 307339.1 ymax: 7330827
## epsg (SRID): 31983
## proj4string: +proj=utm +zone=23 +south +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs
## # A tibble: 130 x 12
## CD_GEOCODI brancos pretos amarelos pardos indigenas sm10mais sm10 sm5
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 353760205… 424 5 31 33 0 24 51 139
## 2 353760205… 154 5 2 41 0 4 23 44
## 3 353760205… 125 1 33 7 0 4 8 35
## 4 353760205… 333 13 17 82 0 6 27 92
## 5 353760205… 267 9 27 86 0 9 21 66
## 6 353760205… 268 26 15 110 0 1 8 55
## 7 353760205… 257 13 10 31 0 6 17 61
## 8 353760205… 338 12 17 81 0 10 35 119
## 9 353760205… 448 10 23 87 0 12 47 146
## 10 353760205… 434 4 8 41 0 10 43 85
## # … with 120 more rows, and 3 more variables: sm2 <dbl>, sm1 <dbl>,
## # geometry <MULTIPOLYGON [m]>Os dados agora estão prontos para ser visualizados.
Passo 4: Criar os mapas
Mapas de raças
pal <- list(
raca = c("yellow2", "dodgerblue", "red", "orange4", "black"),
renda = rev(c("#ffffb2","#fecc5c","#fd8d3c","#f03b20","#bd0026"))
)
leg <- c("Raça", "Classe social")
p <- lapply(1:2, function(i) {
ggplot() +
geom_sf(data = st_geometry(camadas$setores),
col = "grey30", alpha = 0, lwd = .1) +
geom_sf(data = camadas[[i]], aes(colour = categoria),
size = .3, show.legend = "point") +
scale_colour_manual(values = pal[[i]], leg[i]) +
guides(color = guide_legend(override.aes = list(size=2, alpha = 1))) +
ggtitle(paste("Distribuição espacial dos habitantes por", leg[i])) +
light_map_theme()
})
do.call(grid.arrange, c(p, ncol = 2))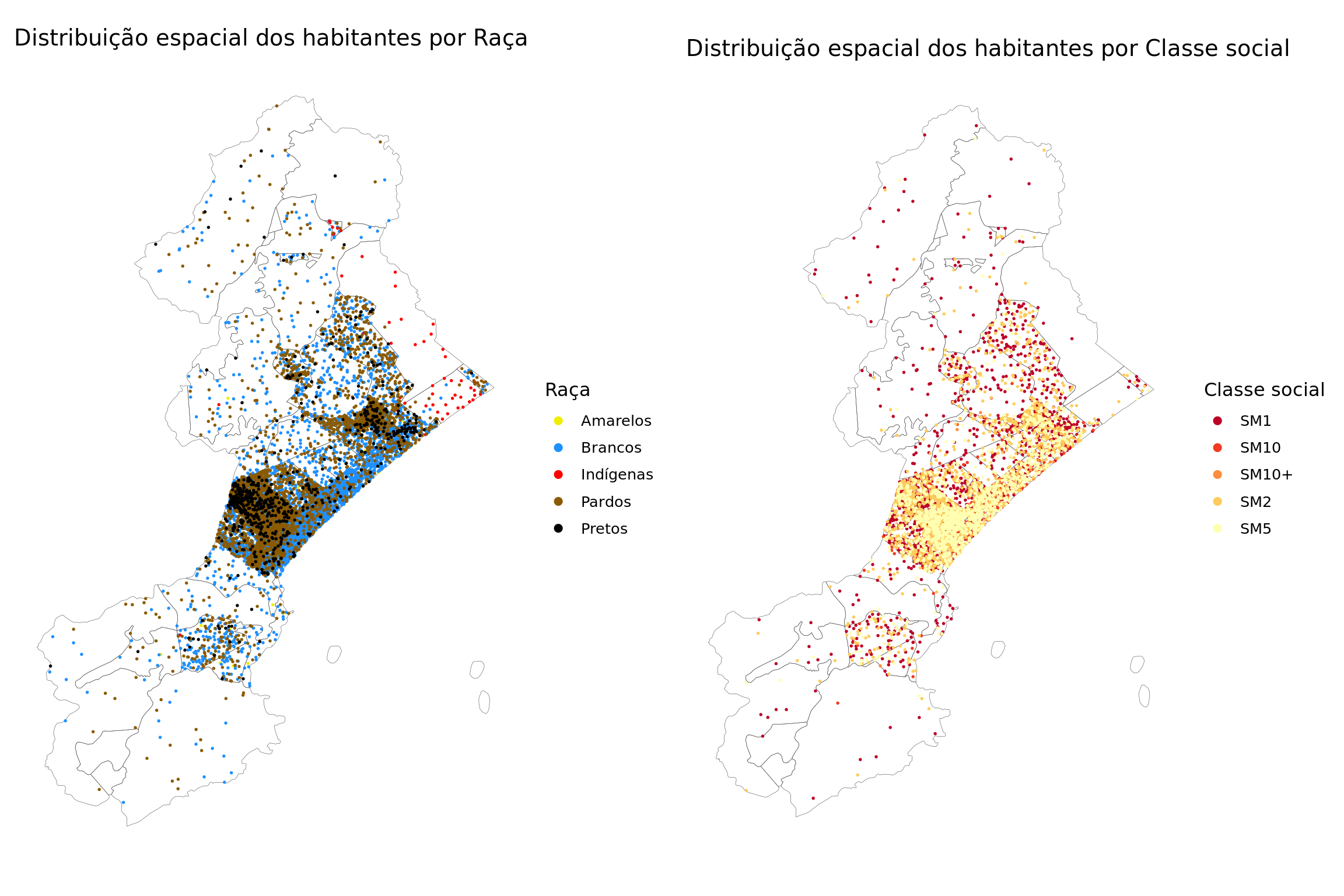
Mapas dos grupos populacionais
p <- lapply(1:2, function(i)
ggplot() +
geom_sf(data = camadas$setores,
color = "grey30", lwd = .06, alpha = 0) +
geom_sf(data = camadas[[i]], aes(colour = categoria),
size = 1.2, alpha = 0.08) +
scale_colour_manual(values = pal[[i]], guide = FALSE) +
ggtitle(leg[i]) +
facet_wrap(~categoria, ncol = 5) +
light_map_theme()
)
do.call(gridExtra::grid.arrange, c(p, nrow = 2))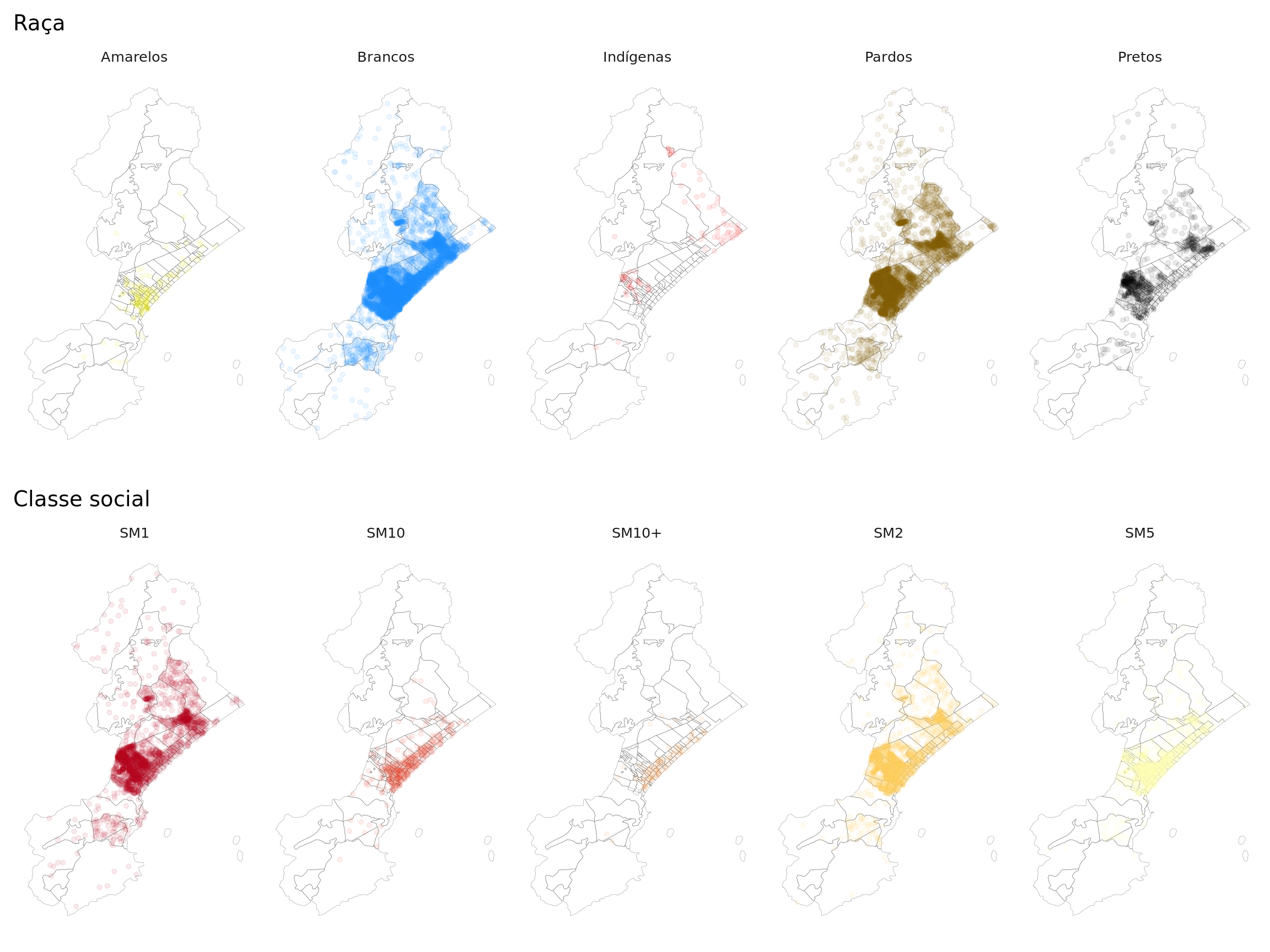
Depois de ver esses mapas, o que você pensa sobre a relação entre renda, raça e local de moradia na cidade de Peruíbe?